關聯式資料庫的概念,是由多個互相有關係的資料表儲存資料並建立關聯。每個資料表是一個實體物件資料,像是我們的animals 資料表,裡面每一筆資料都是物件資料,內容包含動物的所有特性。
我們來整理一下前幾天匯入的另外一張資料表 adoption_gov_animals。如果沒匯入請到前天的文章執行一下SQL
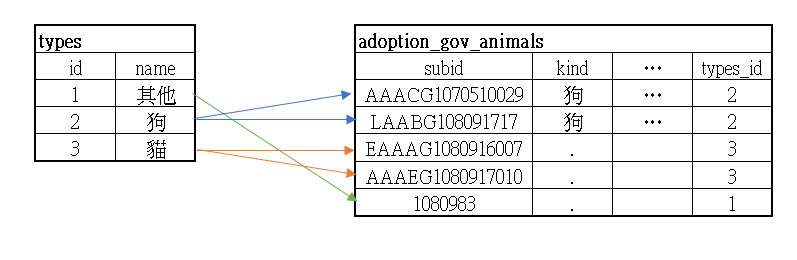
拆分種類資料
adoption_gov_animals 中有一個欄位資料是紀錄動物種,可以用下方SQL執行看看,公開資料有多少種類。
SELECT DISTINCT kind FROM adoption_gov_animals;
顯示結果是有三種,我們把它拆出來到另外一張資料表。先建立一張資料表 types 裡面包含主鍵 id ,以及 name 欄位。其他欄位是紀錄新建以及更新時間。
CREATE TABLE types (
id bigserial PRIMARY KEY,
name varchar(20),
created_at timestamp,
updated_at timestamp
);
建立完成資料表以後,我們把資料寫入 types 資料表
INSERT INTO types(name,updated_at,created_at)
SELECT DISTINCT kind, now(), now() FROM adoption_gov_animals;
成功!我們有一張 分類資料表了!來記錄每一種分類,例如:貓|狗|鳥...
我們建立一個新的欄位在 adoption_gov_animals 欄位名稱為 types_id 來紀錄兩個的關係,欄位類型要跟 types 資料表的 id 一樣(bigint)
--修正資料表
ALTER TABLE adoption_gov_animals ADD COLUMN types_id bigint;
-- 設定其他種類的 types_id 對應到 types 資料表中的 id 1
UPDATE adoption_gov_animals
SET types_id = 1
WHERE kind = '其他';
-- 設定狗種類的 types_id 對應到 types 資料表中的 id 2
UPDATE adoption_gov_animals
SET types_id = 2
WHERE kind = '狗';
-- 設定貓種類的 types_id 對應到 types 資料表中的 id 3
UPDATE adoption_gov_animals
SET types_id = 3
WHERE kind = '貓';
-- 檢查一下是否有沒有關聯到的資料
SELECT * FROM adoption_gov_animals
WHERE types_id is null;
一下子!用到很多東西!在這裡複習一下,
ALTER TABLE 指令,使用時機假設你建立了一張表,但發現有一些錯誤,必須做一些改變,最簡單的方法就是把資料表刪除再建立,但是當資料表中已經有很多資料時,可以使用 ALTER TABLE
UPDATE 修改資料,可以依照篩選條件,查詢出來的資料,做資料的修改,操作之前請務必非常小心,這裡做的預防措施,就是選擇新增一個欄位types_id ,而不是去修改 kind 欄位,不直接去修改kind 的內容,不然Update 完了以後,沒有備份,什麼都來不及了。
上面這一種 稱之為一對多的關聯,一個類別對應到很多動物。
types 資料表中的 id 欄位稱之為主鍵,adoption_gov_animals 資料表中的稱之為外鍵
一對多
舉例:
- 一個使用者對應很多篇PO文
- 一間學校有很多學生
- 一個飼主可以養很多隻貓狗
一對一
較常運用在資料隱私的問題上
假設做一個會員系統
可以把較公開的資料存一個表,比較隱私的部分,比如說生日及電話可以存在另外一張表,然後設定讀取的權限,阻止沒有權限瀏覽隱私資料的人,無法去查詢隱私資料。
用我們公開資料嘗試範例
公開資料認養資料中,有一欄位是 animal_caption 是要給後台人員看而已,一般民眾不需要知道,把資料拆分出來到另外一張表。

CREATE TABLE privacy_adoption_gov_animals AS
SELECT id, caption FROM adoption_gov_animals
WHERE caption is not null;
-- 移除 adoption_gov_animals 資料表中的caption 欄位
ALTER TABLE adoption_gov_animals DROP COLUMN caption;
以上SQL 又用到一個還沒介紹過的方法,常用於備份資料表用, CREATE TABLE ... AS (查詢語句),可以很方便的複製資料表。
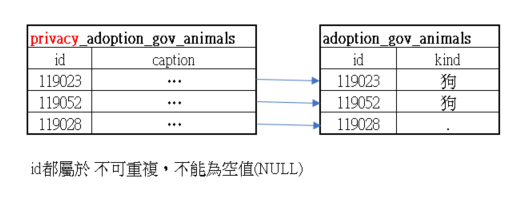
兩張資料表中,ID 都只會出現一次。並且可以對應到 另外一張表的其他資料。
(到目前為止先簡單介紹關聯,還沒有加入約束條件。)
多對多
最常看到的就是文章的 tag 功能,利用一張中間表,去紀錄兩個物件(文章、tag的關係)
我們這裡來製作幫動物加入 TAG 的功能。
建立一張 tags 表格,基本上跟種類的資料表一樣,只差在資料表名稱而已
CREATE TABLE tags (
id bigserial PRIMARY KEY,
name varchar(20),
created_at timestamp,
updated_at timestamp
);
接下來呢,在建立一張中間表,命名為 animal_tag
CREATE TABLE animal_tag (
id bigserial PRIMARY KEY,
animals_id bigint,
types_id bigint,
created_at timestamp,
updated_at timestamp
);
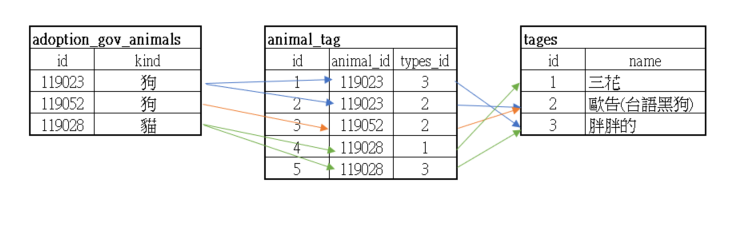
多對多就是這樣的架構,動物可以對應到很多tag,每個 tag 也可以對應到多個動物。

