
爬蟲是一種自動化工具,用於從網頁上抓取資料,Python 提供了許多強大的工具和套件,使得構建爬蟲變得簡單且高效。本文將介紹如何使用 Python 和 BeautifulSoup 套件來構建一個簡單的爬蟲。
使用環境
- MacBook Pro M3 pro
- Python3
- IDE 是 PyCharm (快捷鍵可以使用
⌃R可以執行我們撰寫的python程式)
安裝所需套件
在開始之前,確認系統已安裝 Python 以及相關的套件,可以使用 pip 來安裝所需的套件
如果沒有安裝過 requests
pip install requests如果沒有安裝過 beautifulsoup4
pip install beautifulsoup4步驟
發出請求
首先,我們需要向網頁發送 HTTP 請求,並獲取網頁的 HTML 內容。這裡我們使用 requests 套件來完成這個任務(如果沒有安裝可以使用上面的指令)。
我們使用 PTT 寵物版為例,簡單的確認一下範例的網址有沒有成功請求,HTTP 請求有一些狀態馬, 200 表示請求成功。
import requests
url = 'https://www.ptt.cc/bbs/pet/index1177.html'
response = requests.get(url)
if response.status_code == 200:
print("成功訪問網頁")
else:
print("無法訪問網頁")解析 HTML 內容
獲取到網頁的 HTML 內容後,我們使用 BeautifulSoup 來解析這些內容。BeautifulSoup 是一個 Python 套件,用於從 HTML 或 XML 文件中提取資料。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')程式碼變這樣,在請求成功的區塊中看到把 請求後拿回來的 HTML 給 BeautifulSoup 解析,並且賦予 soup 我們解下來就可以用這個變數方便拿到 HTML中的資訊。
import requests
from bs4 import BeautifulSoup
url = 'https://www.ptt.cc/bbs/pet/index1177.html'
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
print("成功訪問網頁"")
else:
print("無法訪問網頁")取得所需資料
先來一個簡單的HTML,HTML大致上會長這樣,如下所示,當然實際上不會那麼少東西,可以看到 <div class="articles"> 裡面有很多 li ,我們可以利用 BeautifulSoup 解析以後拿到文章的標題還有相關內容,例如:網址。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>簡單的 HTML 範例</title>
</head>
<body>
<h1>我的網頁</h1>
<p>這是一個簡單的 HTML 文件,用於展示如何抓取資料。</p>
<div class="articles">
<h2>文章列表</h2>
<ul>
<li><a href="article1.html">文章 1</a></li>
<li><a href="article2.html">文章 2</a></li>
<li><a href="article3.html">文章 3</a></li>
</ul>
</div>
<div class="footer">
<p>聯絡我們:<a href="mailto:info@example.com">info@example.com</a></p>
</div>
</body>
</html>取得文章標題以及網址,如下範例 html_content 就是上面的HTML,我們用 'div.articles ul li a' 取的陣列,並且跑一個迴圈一一的列出來。
article.text 拿 a 連結的內容 article['href'] 拿到 a 連結 href 元素內容。
soup = BeautifulSoup(html_content, 'html.parser')
articles = soup.select('div.articles ul li a')
for article in articles:
title = article.text
link = article['href']
print(title, link)利用簡單的 HTML 說明方法後,實際 PTT 的結構如下圖,chrome 瀏覽器的 右鍵>檢查 可以看到網頁的 HTML 結構
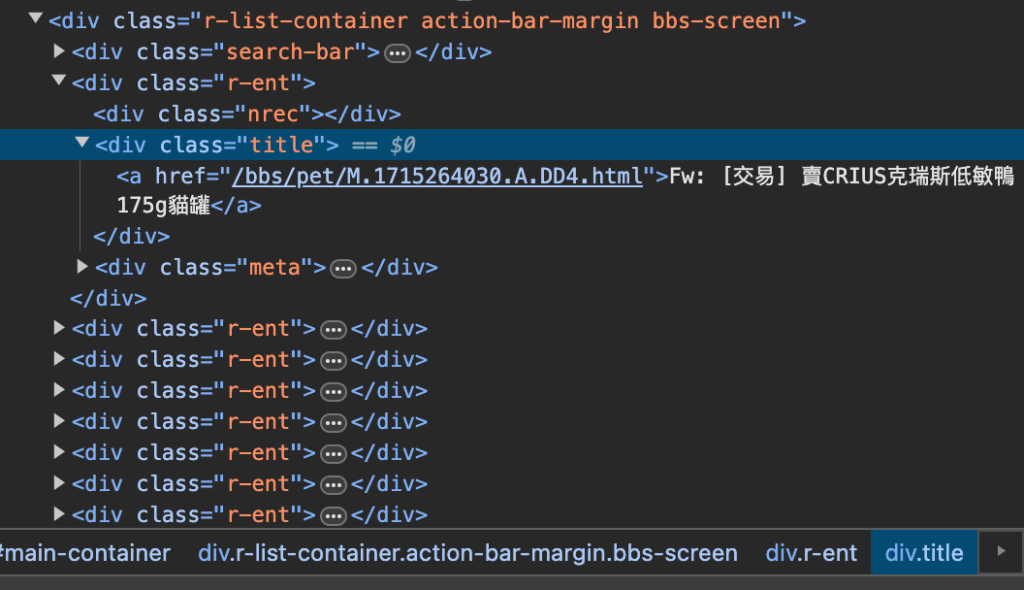
我們可以使用 'div.title a' 拿到標題。
完整程式碼
import requests
from bs4 import BeautifulSoup
url = 'https://www.ptt.cc/bbs/pet/index1177.html'
response = requests.get(url)
if response.status_code == 200:
print("成功訪問網頁")
soup = BeautifulSoup(response.text, 'html.parser')
articles = soup.select('div.title a')
for article in articles:
title = article.text
link = 'https://www.ptt.cc' + article['href']
print(title, link)
else:
print("無法訪問網頁")可以看到像這樣的輸出

結語
今天分享如何使用 Python 以及 beautifulsoup4 套件,來完成取得網頁內容,但實際的爬蟲行為要得別注意,可能涉及法律和道德問題,應該謹慎行事,遵守法律,尊重網站規範,並確保抓取行為不會對他人造成不良影響。
